

Remember binge-watching cartoons on Saturday mornings? And, only the cool kids had TVs in their...
The Colossyan Creator team in the UK recently reached out to Oppida to showcase their DIY AI video generator and test using AI in teaching videos. Their Value Proposition states:
“Leave professional video editing to Colossyan Creator without any training or advanced skills. Simply type in your text and have a video ready in 70+ languages within minutes.”

After reading this, our CEO Bianca’s first reaction was, “NO! Don’t take the coolest part of my job away”. Then, 30 seconds later, she rephrased, “OK, this is awesome. Let’s see what using AI can do and how it compares”.
So, here is the video we entirely produced in a professional studio with an actual human (Bianca), which took at total of approximately 4 hours to produce:
This video is called an “introduction video” to a module. We create these when a course is entirely online and self-paced as it helps bring the learning to life, puts a friendly face to the content, and gives context for the up-and-coming learning journey. Unfortunately, these videos cannot usually be re-purposed and so have a short shelf life (and therefore lower ROI). So, offering clients these videos at a lower cost could greatly benefit them.
Note: When developing a video asset, Oppida follows three stages. PRE-PRODUCTION (scripting and planning), PRODUCTION (filming or producing), and POST-PRODUCTION (editing and embedding).
STEP 1: See what the free version can do
With PRE and POST-PRODUCTION completed for this video, we tasked our resident “techie” (Nim) to re-create the video using AI with the FREE version of Colossyan, as close as he could to the original.
Here is what he could do in about three hours:
STEP 2: Ask the team at Colossyan to recreate.
After not feeling very excited over the first attempt, we contacted the experts to help push the software to the limit.
We provided the full PRE and POST-PRODUCTION notes and assets. Along with brand guidelines and logo. Here is what they came back with (taking approx. 2 hours):
The one major difference with how this video was created was the use of “animations”, where multiple elements can be orchestrated to give the final video a more polished feel.
Comparing the three
Heard of Mayer’s 15 multimedia principles? If not, do check out this blog all about them:
https://elearningdesigners.org/infographics/guidelines-from-mayers-15-multimedia-principles/
We decided to use these principles as a scorecard to assess the THREE versions of the same video and rate using AI versus human in teaching videos.
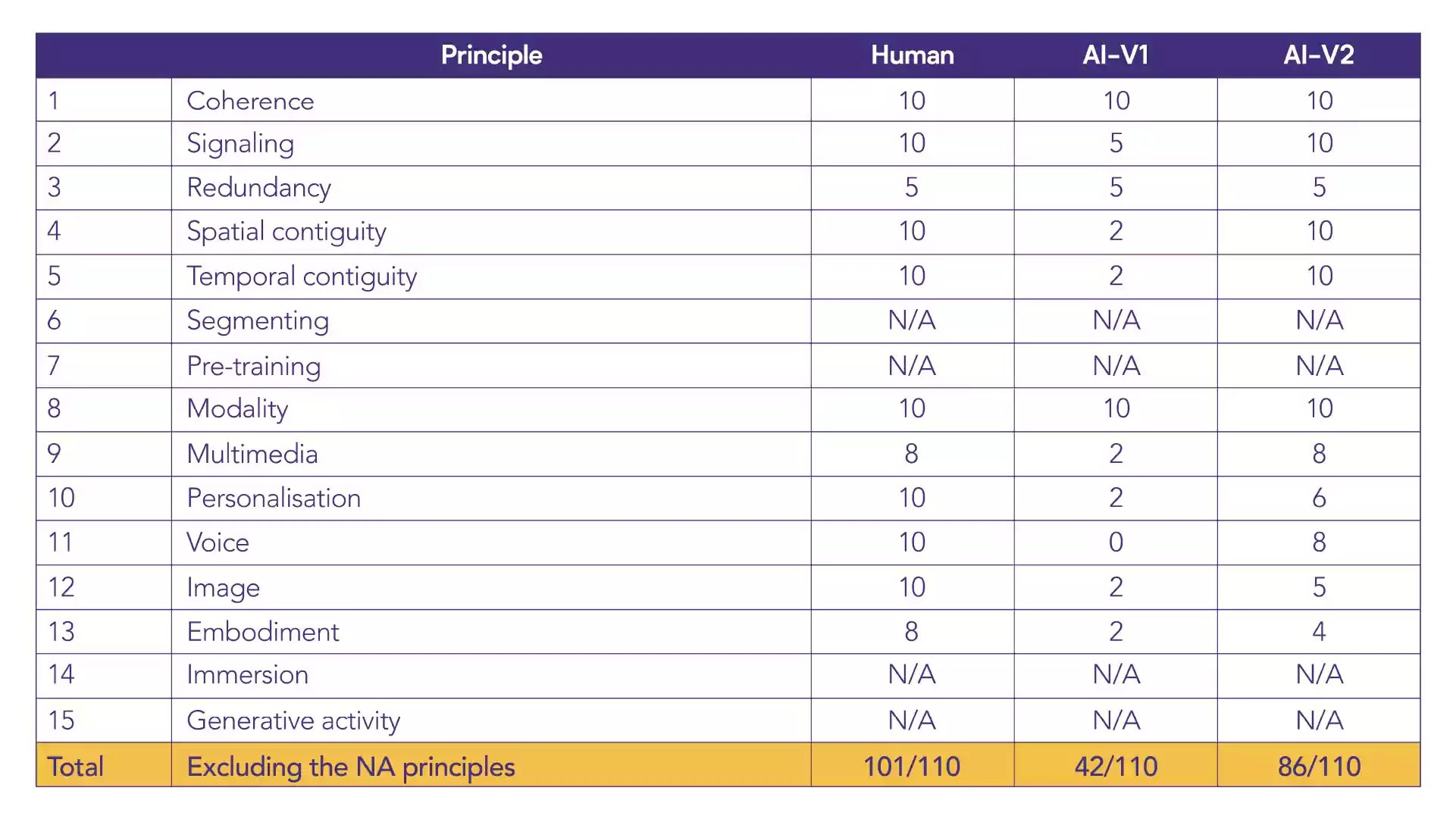
Summary – HUMAN
Displays some redundancy due to reading outcomes from the screen (although these are also key points). Images used to illustrate key points along with text in some cases (attributes of a learning designer) – potential to add further images when discussing portfolio using narrative only. The human voice and talking head style video would generally feature the instructor – live video rather than a still image to increase engagement. Although promising, the embodiment principle suggests eye contact can detract from what’s on the screen. Embodiment can be increased by using natural whole-body movements, gesturing at graphics on the screen, and instructors engaging in drawing tasks on boards, etc. In this case, it could be improved by including a more significant number of natural hand gestures pointing toward graphics.

Summary – AI Version 1
When using AI in the first version, minimal signaling as intonation is not natural, which removes any vocal emphasis. Redundancy due to reading outcomes from the screen (although these are key points present in the human video). Minimal opportunities for spatial and temporal contiguity as only one image was used (Oppida LDP badge) in addition to generic background images. A video clip of the learning designer was shown working in the dark and looking anxious – a mismatch with a message in the previous human video, which was more positive. Duplicated word on the outcomes screen, ‘the the,’ also results in duplicated narration. Multimedia principles of providing graphics and text are not followed – text is only offered to attributes of a learning designer rather than the graphics added to the human version.
Regarding the personalisation principle – the overall intended tone of the message was conversational, although when using AI, the delivery reduced this impact to a formal monotonous one. The voice principle is marked at 0 due to this principle relating to the use of a human voice over a machine voice for narration. The embodiment principle also scored low due to the lips being out of sync with the voice; hands looking as if from a different ‘person’ to the face. Natural hand gestures would generally increase embodiment; however, these gestures seemed out of place and were distracting. The instructor’s face remained fixed and almost entirely still throughout.
This version certainly elicits what has been dubbed the “Uncanny Valley”:
“The phenomenon has implications for the field of robotics and artificial intelligence. Devices and online avatars that are made to help mimic the human touch may actually end up alienating people who are using such tools. “

Summary – AI Version 2
When using AI in the second version, signalling improved – this now matches the human video. Again, the same redundancy principle applies throughout due to reading outcomes from a slide. Multimedia use has been improved to include images from the human version of the video (although the anxious learning designer video clip remains). Images are appropriately spaced with text and images provided simultaneously where applicable. Although the voice quality sounds more human-like, it still lacks the authenticity of the human version, with the audio slightly out of sync with facial expressions. The image in this video is more human-like, with more facial expressions and hand gestures – although using AI is not a match for the human version. An onscreen video clip of the instructor’s face when narrating has been included alongside audio narration, graphics, and text on slides. This increases the cognitive load (Sweller), which Mayer’s principles seek to avoid.

Final thoughts
For Learning Designers, the key challenge is not whether using AI tools like Colossyan or ChatGPT, but when to use them based on the benefits and limitations they offer. Text-to-video features can speed up video creation, editing, and localisation, leading to faster feedback cycles and increased stakeholder satisfaction. Customised avatars can also eliminate scheduling conflicts and allow for diverse communication styles that manage DEI considerations effectively.
However, Colossyan is not the best fit for all situations, as its production quality may not match that of higher-end video productions. While AI avatars can help reduce video production costs and time, they do not solve the critical skills gap in deciding when and how to use video for educational purposes. For the Oppida team, the PRE and POST parts of video production require the most technical human skills, including deciding what to teach and how to write a compelling script.
Colossyan offers a way to provide media options to clients with lower budgets and allows for last-minute script changes. An introduction video made with Colossyan can also be edited with minimal costs and used more than once. We estimate that Colossyan could save anywhere between 30-80% of production costs.
Overall, the Oppida team is excited about using AI tools like Colossyan to enhance online learning and raise the bar in video production.
References
https://www.verywellmind.com/what-is-the-uncanny-valley-4846247

